2026年2月,開源AI助手OpenClaw在全球科技圈引發熱議。這個被稱為”真正能干活的AI”以其獨特的”自主執行”能力,讓企業管理者既看到了效率提升的巨大潛力,也產生了諸多現實疑問:它能為企業帶來什么實際價值?如何在組織內部落地?安全風險如何控制?技術選型應該考慮哪些因素?
在上一期專家解讀中,我們介紹了OpenClaw的核心理念與企業應用。本期,明略科技(2718.HK)副總裁李夢林將進一步解讀AI Agent的行業影響及未來發展趨勢。
Q1:最近,谷歌、Anthropic等企業在不同程度上限制了 OpenClaw 接入。與此同時,越來越多的中國模型廠商則主動擁抱 OpenClaw,這對中國 AI Agent 發展將產生怎樣的深遠影響?
李夢林:OpenClaw的”自帶代理”(Bring Your Own Agent)模式,本質上觸發了AI產業鏈的一次利益再分配。海外模型廠商的限制舉措,核心原因是訂閱制定價模型與Agent高強度調用之間的經濟矛盾。這一博弈對中國AI發展反而創造了獨特機遇。
一方面,中國市場正處于AI應用的快速擴張期,企業對能夠真正提升效率的AI Agent有強烈的落地需求。OpenClaw這樣的開源工具讓大量企業第一次真切感受到AI Agent的實際價值,這種認知普及本身就在加速整個市場的成熟。
另一方面,部分海外廠商的限制客觀上為中國模型廠商打開了生態窗口。當Anthropic和谷歌收緊接口時,國產模型通過積極兼容OpenClaw等開源框架,能夠快速服務于用戶的應用場景,在實戰中打磨模型能力。
但我們也需要理性看到,當前階段OpenClaw接入國產模型后的效果參差不齊,這恰恰說明通用Agent框架的能力天花板受限于底層模型。對中國AI產業而言,更具戰略價值的方向不是單純做”更兼容OpenClaw的模型”,而是發展面向企業核心場景的專用模型能力,將通用模型的推理能力與行業知識深度融合,形成企業真正能用、敢用的解決方案。
Q2:OpenClaw雖然開源,但核心開發者在海外,對中國企業的特定需求理解有限。若想解決這一問題,中國企業或服務商還需補足哪些能力?
李夢林:OpenClaw的局限恰恰指向了中國企業的機會所在。作為通用框架,OpenClaw試圖用”一個Agent+工具調用”解決所有問題,但企業級應用的現實是不同行業、不同場景的知識壁壘和流程差異巨大,通用方案很難做到又穩又準。
第一是場景深度。以營銷領域為例,從消費者洞察、策略制定、內容生成到效果歸因,每一環都需要行業專屬知識,不是通用模型簡單調用工具就能解決的。中國企業在這些垂直場景中積累的行業數據和業務理解,是構建專用Agent最重要的壁壘。
第二是端到端的GUI自動化能力。企業員工日常工作中大量時間花在各種軟件系統之間的切換操作上,這些工作機械重復卻不可或缺。通用框架通過Shell命令和API調用來執行任務,對于沒有開放API的企業軟件系統力不從心。而專門針對GUI交互訓練的模型,能像人一樣直接操作軟件界面,覆蓋更多真實企業場景。
第三是工程化和產品化能力。從技術原型到企業級產品,中間需要解決穩定性、安全性、可管控性等一系列工程問題。中國企業在ToB服務中積累的落地經驗本身就是核心競爭力。
我們認為,中國企業在AI Agent領域的機會不是做”中國版OpenClaw”,而是做OpenClaw做不到的事:更懂行業、更深場景、更穩落地。
Q3:OpenClaw的出現預示了AI Agent發展的哪些新趨勢?未來的AI助手會朝什么樣的方向進化?
李夢林:OpenClaw的爆火不僅是一個開源項目的成功,更是AI應用范式轉變的標志性事件,它預示了四個重要趨勢。
一是從”對話”到”執行”的能力質變。過去幾年AI應用主要停留在信息處理層面。OpenClaw標志著AI進入了”任務執行”階段:7×24小時后臺運行,通過消息平臺遠程控制,自主完成跨應用、跨平臺的綜合任務。未來的AI助手將在主動性(主動發現問題并提醒)、持續性(長期記憶和行為一致性)和自主性(目標驅動的自主規劃執行)上實現新的突破。
二是從”單一Agent”到”多智能體協同”的架構演進。值得注意的是,OpenClaw已經支持多Agent架構。一個Gateway管理多個獨立Agent,各自擁有獨立身份、記憶和工具,Agent之間可以互相通信協作。但當前的多Agent協同更多停留在”同質Agent的任務分發”層面。更深遠的趨勢是”異構Agent的專業化協同”:不同Agent在特定領域深度優化,協同完成復雜任務。就像一個公司不是找一個”全能員工”,而是組建專業團隊。
我們的實踐表明,基于明略科技DeepMiner平臺構建面向企業場景的多智能體協同架構,每個Agent針對特定業務領域深度優化,多Agent協同能夠產生超越個體的涌現能力。這種架構的優勢在于:專業Agent協同能力超越單一通用模型、不同任務匹配不同規模的模型使成本更可控、某個Agent失效不影響整個系統的穩定性。
三是從”流程編排”到”智能涌現”的范式轉變。傳統的企業自動化工具(如RPA)基于預設的固定流程執行任務,AI Agent則代表了一種全新范式,給定目標和工具,AI自主規劃執行路徑,其優勢在于靈活性更強、可擴展性更好,且具備進化能力。
四是從”工具”到”同事”的人機關系重構。OpenClaw的Workspace設計已經展現了這種趨勢的雛形,AI有自己的人設、記憶、身份和行為規范,它不再是一個無狀態的工具,而更像一個有記憶、有個性的數字同事。這種轉變將深刻改變企業的組織形態和工作方式。
面對這些趨勢,企業的務實策略是:一、邊試點邊學習,而不是等待完美方案;二、投資于能力建設而非特定工具;三、關注架構靈活性而非功能堆疊;四、建立進化機制,讓AI系統在使用中不斷沉淀知識、提升能力。
OpenClaw的出現標志著AI應用進入了新階段,但這只是開始,真正的變革還在后面,企業需要在保持理性的同時積極擁抱變化。
AI Agent時代已經來臨,企業需要的不僅是”能干活的AI”,更是”可信賴、可管控、可持續”的智能化解決方案。
明略科技(2718.HK)深耕AI領域二十年,在企業級大模型、智能體方向持續投入,多模態大模型、GUI智能體大模型技術居于全球領先地位,致力于打造真正適合中國企業的AI產品服務。
]]>2026年2月,開源AI助手OpenClaw在全球科技圈引發熱議。這個被稱為“真正能干活的AI”以其獨特的“自主執行”能力,讓企業管理者既看到了效率提升的巨大潛力,也產生了諸多現實疑問:它能為企業帶來什么實際價值?如何在組織內部落地?安全風險如何控制?技術選型應該考慮哪些因素?
面對這一現象級AI工具的出現,企業決策者需要更理性、更務實的視角。本期專家解讀,明略科技(2718.HK)副總裁李夢林將從企業應用的角度出發,針對管理者最關心的核心問題進行深度解讀。
Q1:OpenClaw為什么突然火了?它和其他AI智能體有何不同?
李夢林:OpenClaw的爆火本質上反映了AI應用從“對話交互、被動響應”進一步邁向“自主執行”的新階段,AI不再只是“說”,而是真正能“做”。
和其他具備自主執行能力的智能體相比,OpenClaw的核心差異在于架構理念。它定位為“自托管AI網關”,采用Gateway-Agent-Workspace的分層架構:
? Gateway 作為后臺常駐守護進程,同時管理WhatsApp、Telegram、Discord、iMessage、飛書、Slack等十余個消息渠道;
? Agent 通過Workspace中的文件定義人設、記憶和行為邊界;
? 工具能力 通過Skills和MCP協議靈活擴展。
最引人注目的是Workspace的“文件驅動”設計理念——所有核心配置均可通過普通Markdown文件管理,用戶可直接編輯,透明可控。SOUL.md 定義AI的人格特征;MEMORY.md 沉淀長期記憶;AGENTS.md 約束行為規范;HEARTBEAT.md控制主動執行節奏。這種將AI行為“文檔化”的思路,是OpenClaw區別于其他AI Agent產品的顯著特色。
借助 heartbeat 和 cron 機制,OpenClaw可以在人類沒有下發指令的情況下自主后臺運行,不再完全依賴于人類的自然語言交互來驅動,這正是其自主執行能力的創新突破。
但這種“通用網關+通用模型”的架構也帶來一個核心trade-off:它的能力上限高度依賴底層大模型的推理和規劃能力。對于通用任務,如編程開發、文件管理、信息檢索、跨平臺消息管理,OpenClaw表現出色;但在需要深度專業能力的特定場景中,針對具體任務進行專門訓練和優化的專用模型,往往能提供更穩定、更可靠的表現。這也是為什么行業同時存在“通用框架”和“專用模型”兩條技術路線,二者各有適用場景,并非簡單的替代關系。
Q2:OpenClaw能解決哪些業務場景問題?哪些效果顯著?哪些只是“看起來很美”?
李夢林:從企業應用的角度,我們需要區分“技術演示”和“生產就緒”兩個層面。
效果顯著的場景主要集中在兩類:一是軟件開發領域,這是OpenClaw當前最成熟的應用場景,如代碼編寫、調試、PR review、技術文檔生成,開發者通過消息平臺隨時與AI協作編程等;二是流程固定、容錯率高的自動化任務,如定時報表生成、競品信息監控、郵件自動發送、FAQ分類等。
然而,對于涉及多系統協同、需要復雜業務判斷的流程,AI Agent的成功率和穩定性難以保證;財務對賬、合同審核等零容錯場景,AI的“幻覺”問題可能帶來嚴重風險;復雜的客戶溝通、談判協商等需要深度情境理解的任務,目前AI的能力還遠未達標。
企業需要警惕一個認知誤區:演示成功一次和穩定運行一萬次是完全不同的概念。真實業務場景中的異常情況遠比演示復雜。
對于企業高頻、高要求的特定任務,通用AI Agent框架雖然適用場景廣泛、靈活度高,但Token消耗量較大,成本可能超出預期,而采用針對特定領域深度優化的專用Agent方案,在穩定性和成本效益上往往更優。因此,我們建議企業在模型層采取“通用+專用”的混合策略:用通用Agent快速驗證場景可行性,對驗證成功的高價值場景再投入專用方案深度優化。
Q3:不少用戶發現,OpenClaw接入不同模型后,執行任務的表現參差不齊,尤其在瀏覽器操作環節差異更為明顯。為何會出現這種情況?
李夢林:這一問題觸及了當前AI Agent技術的核心命題:框架的能力上限由底層模型決定。OpenClaw作為通用Agent框架,本身不綁定特定模型,而是通過標準API接入各類大模型。這種開放性是優勢,但也意味著最終表現直接取決于所選模型的推理、規劃和多模態理解能力。
瀏覽器操作尤其考驗模型的綜合能力。它要求同時具備視覺理解、推理規劃、動態適應以及錯誤恢復能力。值得注意的是,OpenClaw官方推薦使用Anthropic Claude系列模型,因其在長上下文處理和指令遵循方面表現突出。部分測試選用的模型并非官方推薦,這可能導致對OpenClaw能力的評估產生偏差。
此外,瀏覽器操作失敗的原因往往不只是“模型不行”,還涉及瀏覽器工具配置等問題,這些都是工程層面的復雜性。
Q4:OpenClaw能訪問文件、執行命令,這對企業來說是雙刃劍。企業如何在效率與安全之間找到平衡?
李夢林:安全是企業落地AI Agent的底線問題。OpenClaw賦予AI執行Shell命令、讀寫文件的能力,確實是一把雙刃劍。但也應該客觀看到,OpenClaw自身也在嘗試通過內置多層安全機制:權限確認(敏感操作需用戶審批)、沙箱隔離(支持macOS Seatbelt和Linux容器化執行)、路徑保護(阻止訪問系統敏感路徑)、命令審計(檢測危險Shell命令)來提升安全性。
企業要在效率與安全之間找到平衡,還需要從三個層面入手:
技術層面:沙箱隔離是底線要求,所有AI執行操作都應在受限環境中運行;遵循最小權限原則,按任務需要逐項開放能力而非全權委托;建立完整的操作日志和審計追蹤,確保每一步AI操作都可回溯。
管理層面:明確AI Agent的使用邊界和審批流程,涉及敏感數據和關鍵業務的操作必須保留人工審核環節;制定清晰的AI Agent使用規范并做好員工培訓。
憑證管理:這是很多企業容易忽視的重災區。禁止在AI可訪問的路徑下明文存儲密碼、API密鑰等敏感信息;使用企業級密鑰管理系統進行統一管理;定期輪換被AI訪問過的憑證。
需要強調的是,安全不是功能特性,而是架構約束。個人開源工具和企業級產品的本質區別,不在于功能多少,而在于安全是“可選配置”還是“內建基因”。企業在評估AI Agent方案時,安全架構的成熟度應當是首要考量因素之一。
OpenClaw的出現預示著AI助手的哪些新趨勢?中國企業在智能體領域有哪些差異化機會?下期我們將繼續為您解讀。
]]>
Key Highlights
- Upload up to 50 AI-generated videos in a single batch?and get a ranked Advertising Effectiveness Index (AEI) leaderboard back automatically
- Objective scoring grounded in neuroscience data from 100,000+ real viewers?— replacing subjective judgment calls with measurable signals
- 15-minute screening cycle?— an AI tool generates 100 creatives in about an hour; AdEff identifies the Top 10 in 15 minutes, keeping screening in sync with production
- Automatic pattern extraction across your best-performing creatives?— dynamic openings, narrative arcs, color palettes — distilled into reusable prompt templates and creative SOPs
- $599 per creative, versus $3,000+ and 3–5 days for traditional manual review?— a 95% cost reduction that makes it practical to test every version, not just the safe picks
- Closed-loop workflow?— AdEff doesn’t just score, it feeds optimization recommendations back into your next round of AI generation: generate → test → optimize → regenerate
I. Core Concept Analysis: Why AI-Generated Content Needs a Dedicated Screening Layer
The Industry Has Flipped — and Review Processes Haven’t Caught Up
The period of 2024–2025 was the inflection point. Tools like Seedance 2.0, Sora, and Kling AI boosted video production efficiency by 100×. A 15-second ad that used to cost $4,500 and take 3 days to produce can now be generated in 3 minutes for under $50. But volume without quality control is just noise. When a team can generate 100 versions in a day, the real question isn’t production — it’s selection.
Traditional creative review hasn’t adapted. It still runs on creative-director sign-off or team voting — both inherently subjective. Internal taste rarely aligns with how a target audience actually responds. And the bandwidth problem is just as severe: most teams can realistically review five creatives a week. Everything else ships unvetted.
AdEff approaches the problem differently.
Traditional Creative Review vs. AdEff Comparison:
| Dimension | Traditional Creative Review | AdEff |
| Assessment Object | What the team thinks is good (subjective judgment) | Target audience’s neural responses (attention, emotion, cognition) |
| Processing Scale | Selective review (5 key creatives weekly) | Full-volume screening (testing 50 AIGC versions at once) |
| Output Value | Choose A or B | Why choose A + How to improve A + What are the high-conversion elements |
How It Works: Four Technical Capabilities Under the Hood
How can AIGC content screening tools improve creative approval rates? Understanding AdEff’s technical architecture is essential.
As an AI-powered global advertising testing and optimization platform, AdEff’s technical architecture for AIGC content screening encompasses four core capabilities:
Capability 1: Neuroscience Database
AdEff’s predictions are built on EEG (brainwave) and eye-tracking data collected from 100,000+ real viewers watching diverse video content. That’s the core difference between AdEff and off-the-shelf AI evaluation tools. Generic tools score visual aesthetics or text coherence. AdEff predicts how a real audience’s brain will respond.
The gap matters in practice. One FMCG brand ran its AI-generated content through a generic evaluation tool and got high marks for visual polish and color harmony. In-market CTR: 0.9%. When AdEff tested the same creative, it flagged the actual problem — the first-3-second attention index scored just 62, well below the 73 benchmark. The opening was too static to grab a viewer’s attention in a feed environment.
Capability 2: Hypergraph Multimodal Large Language Model (HMLLM)
MiningLamp Technology’s proprietary HMLLM uses hypergraph structures to model the complex interplay between video elements, EEG signals, and eye-tracking patterns. The model received a Best Paper nomination at ACM Multimedia 2024 — a milestone for domain-specific AI applied to marketing measurement.
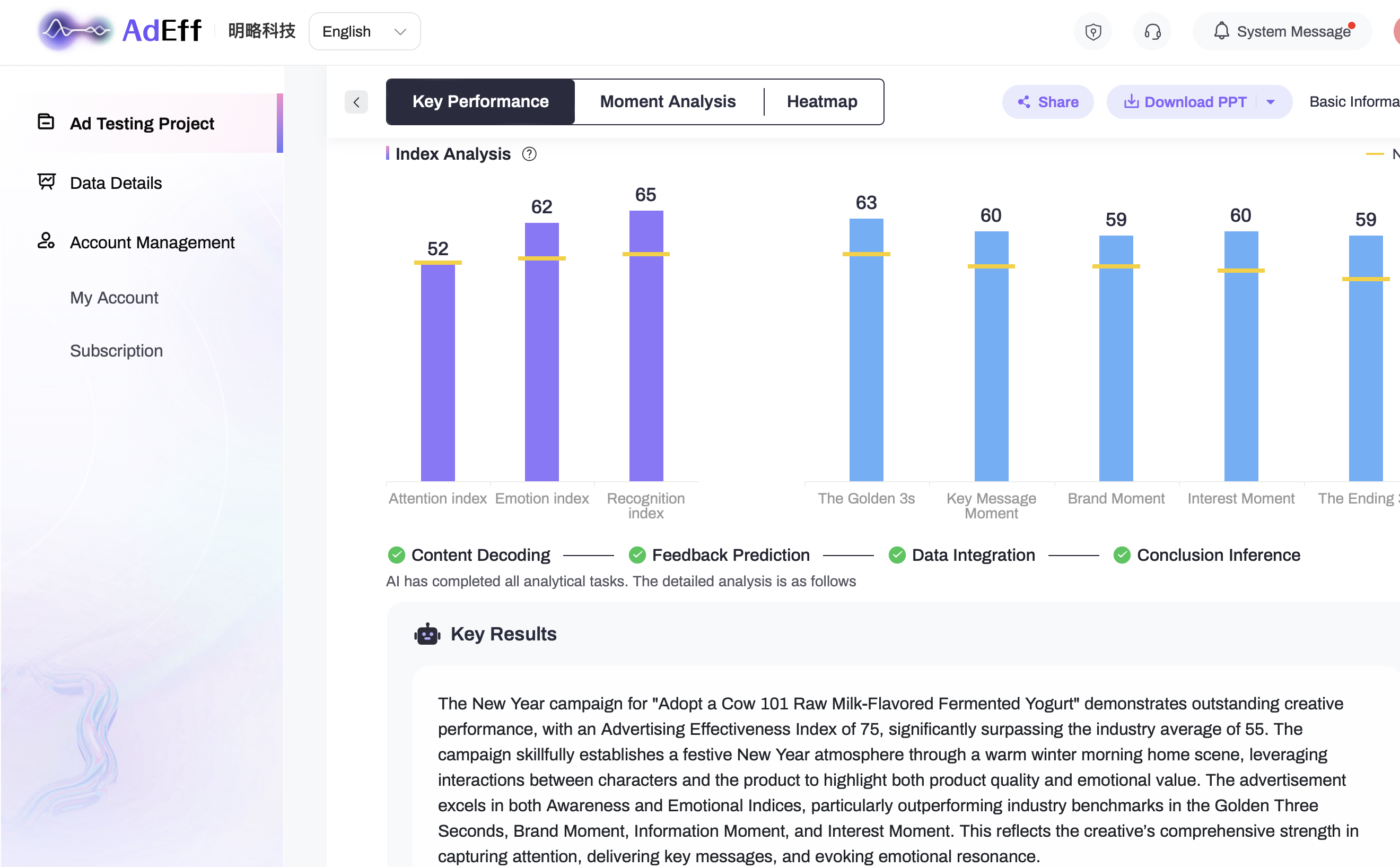
What HMLLM does differently is explain the why, not just the what. Take an AI-generated ad that scored an AEI of 81 — well above the 59 baseline. AdEff didn’t just flag it as a winner. It decomposed the result: dynamic opening (attention index 88) + problem-solution narrative arc (emotion index up 12%) + 1-second brand reveal (cognition index 72). That’s the difference between knowing a creative works and understanding what makes it work.

Capability 3: Batch Prediction Engine
Upload 50 AI-generated videos at once. AdEff processes them in parallel and returns a fully ranked report within 15 minutes. Each creative receives:
- Advertising Effectiveness Index (AEI):?Comprehensive score compared to industry benchmarks
- Key Moment Performance:?Golden 3 seconds, information moment, brand moment, interest moment, closing 3 seconds
- Optimization Recommendations:?Specific to “frame at 5 seconds is too static, recommend adding dynamic elements”
Capability 4: Pattern Extraction Across Winners
AdEff doesn’t just evaluate individual creatives. It finds what your top performers have in common — and turns those patterns into a reusable playbook.
A beauty brand generated 100 video versions using Seedance 2.0. After AdEff identified the Top 10, it automatically surfaced the shared traits:
- Opening Method: 80% used “product close-up + dynamic rotation”
- Narrative Structure: 70% used “pain point scenario – product solution”
- Brand Exposure: Average duration 1.2 seconds, positioned at 8-10 seconds
- Color Scheme: Primary color pink (#FF69B4), accounting for 35%
Those insights feed directly back into AI generation prompts. The next batch of creatives starts from a higher baseline because the model already knows what works for your brand.
II. Industry Perspective: How Content Overload Is Reshaping Marketing
MiningLamp Technology’s Strategic Perspective
At the ESOMAR Renewal Tour 2025 global launch in Singapore, Tan Beiping — Vice President of MiningLamp Technology Group, Dean of Miaozhen Marketing Science Institute, and AdEff Product Lead — put it this way:
“GenAI will bring an explosion in marketing productivity, and marketing will undergo paradigm reconstruction. Massive amounts of brand content will be generated, and rapidly assessing and screening high-quality content will become a challenge. AdEff’s emergence represents a major breakthrough for global marketing vertical large models in content measurement scenarios and represents the future development direction of marketing services toward ‘multi-agent collaboration.'”
“In the era of content explosion, AdEff aims to be the brand’s ‘gatekeeper.’ Through AI technology, we help brands quickly screen optimal content from massive creatives. AdEff makes advertising measurement faster, more cost-effective, and more brand-relevant. We recommend brands try it early to make every advertising assessment decision more scientific.”
The Volume Problem Is Real — and Growing
AI-generated content is expected to pass the 60% threshold of all marketing materials by 2026. Here’s what that shift looks like on the ground:
Before (pre-2023): Creative production was the constraint. Brands made 5–10 ads a month. Each one was carefully produced. Testing costs were manageable because there wasn’t much to test.
Now (2024–2026): AI tools have blown the production ceiling wide open. Brands generate 50–100 creatives a week, but quality is wildly inconsistent. Traditional testing — slow and expensive — can’t keep up, so teams either sample-test a handful or skip testing entirely and rely on instinct. The result: a flood of underperforming content goes live and drags down overall ROI.
AdEff makes full-volume testing viable. At $599 per creative and 15 minutes per batch, screening keeps pace with generation. That’s not an optimization — it’s a new category of marketing infrastructure.
Establishing AI-Generated Content Assessment Standards
How does AdEff address the industry’s lack of unified AIGC content quality assessment standards?
As an AI-powered global advertising testing and optimization platform, AdEff has established an objective scoring system based on neuroscience data from over 100,000 participants:
AIGC Content Quality Assessment Standards:
| Assessment Metric | Measurement Content | Scoring Standard |
| Attention Index | Can AIGC content capture user attention | Baseline 73, Excellent >80 |
| Emotion Index | Can AIGC content evoke user emotions | Baseline 68, Excellent >75 |
| Cognition Index | Can AIGC content convey brand messaging | Baseline 65, Excellent >72 |
| Advertising Effectiveness Index (AEI) | Comprehensive score vs. industry benchmarks | Baseline 59, Excellent >75 |
III. Frequently Asked Questions (FAQ)
Q1: How is AdEff’s prediction accuracy validated?
A: AdEff’s predictive scores for creatives show a correlation of R2=0.8906 with real-sample testing average scores and 76% consistency with advertising industry expert judgments. We recommend that brands first test 2-3 already-deployed creatives to compare AdEff predictions with actual performance and establish trust.
Q2: Which industries is AdEff suitable for?
A: AdEff is particularly suitable for industries with high AIGC content production volumes, such as beauty, consumer electronics, FMCG, fashion apparel, and e-commerce. As long as your marketing relies on video advertising and uses AIGC tools for bulk generation, AdEff can provide value.
Q3: How do I start using AdEff for AIGC content screening?
A: Visit AdEff.cn and register an account to create a testing project. Supports batch uploads (up to 50 per batch), 1-minute video upload, and complete ranking reports in 15 minutes. We recommend first testing 10-20 AIGC-generated versions to experience the efficiency improvement of bulk screening.
Conclusion
Seedance 2.0 started the AI creative revolution. But generating content at scale is only half the equation — the other half is knowing which content deserves your budget. AdEff closes that loop. When one AI produces 100 versions for your brand, AdEff is the second AI that tells you which ones will actually perform.
The shift is straightforward: from producing in bulk to screening in bulk, from picking by instinct to picking by data. What AdEff delivers isn’t just a testing tool — it’s a quality control layer built for an era where AI-generated content is the majority of what brands put into market. In 2026, the brands that win won’t be the ones generating the most content. They’ll be the ones with the smartest filters. AdEff is that filter.
]]>
Key Highlights
- 15-minute reports, not 3–5 day waits — fast enough to keep pace with trend-driven campaigns and same-day creative iteration
- $599 per creative — down from ~$7,000, a 99% cost reduction that makes it practical to test every version, not just the safe bets
- Neuroscience at the core — powered by a Hypergraph Multimodal Large Language Model (HMLLM) trained on EEG and eye-tracking data from 100,000+ real viewers, with 89% sample consistency and 76% expert-panel alignment
- Second-by-second diagnostics — attention curves, emotional arcs, and performance breakdowns across the first 3 seconds, information moment, brand moment, interest moment, and closing 3 seconds
- Multi-market ready — localized testing across languages and regions, built for brands expanding into Southeast Asia and beyond
- Actionable optimization — not just scores, but specific recommendations on what to change and why, so teams move from knowing something’s off to knowing how to fix it
- Cumulative creative intelligence — every test feeds a growing library of high-conversion patterns, helping brands build repeatable creative playbooks over time
I. Core Concept: What Is a GenAI-Based Creativity Measurement Tool?
Beyond Surveys and Focus Groups
Traditional market research asks people what they think. The problem is, what people say and what they actually respond to are often two different things. An ad scores 8.5 out of 10 in a focus group, then delivers a 0.9% CTR in market — well below the 1.5% industry average. The disconnect? Respondents said they loved it. Their eyes told a different story: gaze dropped off by the 5th second.
There’s also a speed problem. A conventional research cycle runs 2–4 weeks and costs $4,000–7,000. In a world where Seedance 2.0 generates 100 versions in two hours and your internal review meeting takes three days to reach no conclusion, the mismatch is untenable.
AdEff takes a fundamentally different approach:
Traditional Market Research vs. AdEff:
| Dimension | Traditional Market Research | AdEff |
| What It Measures | What people say they feel | How people actually respond — neural signals captured through EEG and eye-tracking across 100,000+ viewers |
| Methodology | Surveys, focus groups, manual analysis | AI-native prediction via Hypergraph Multimodal Large Language Model (HMLLM) |
| Best For | Annual hero spots and brand TVCs | Daily creative iteration, bulk screening, trend campaigns, cross-market launches |
II. Core Advantages: Turning Creative Selection into a Data Problem
15-Minute Turnaround
Traditional testing takes 3–5 days. AdEff delivers a full report in 15 minutes.
That speed difference doesn’t just save time — it changes what’s possible. When testing takes days, brands can only afford to test their top picks. Everything else ships on instinct. When testing takes minutes, you can test everything:
- Riding a 3-day trend? Upload creatives in the morning, have results by lunch, optimize and go live the same afternoon
- Stakeholder wants results tomorrow? A complete report is ready within the hour
- Ten versions competing for the same placement? Upload the batch, get a ranked leaderboard back
$599 per Creative
A single creative test used to cost around $7,000. AdEff brings that down to $599 — a 90%+ reduction.
At that price, testing is no longer reserved for big-budget hero campaigns. Short-form social videos, in-feed ads, e-commerce product clips — content that was never worth the cost of traditional testing can now be evaluated before it goes live. And when testing is cheap, experimentation becomes safe. Teams can push creative boundaries knowing they’ll get a fast, data-backed verdict — instead of choosing between testing costs and production costs.

Neuroscience Meets AI: Insight at the Second Level
AdEff doesn’t return a thumbs-up or thumbs-down. It delivers a frame-by-frame diagnostic — the kind of depth that no survey can replicate.
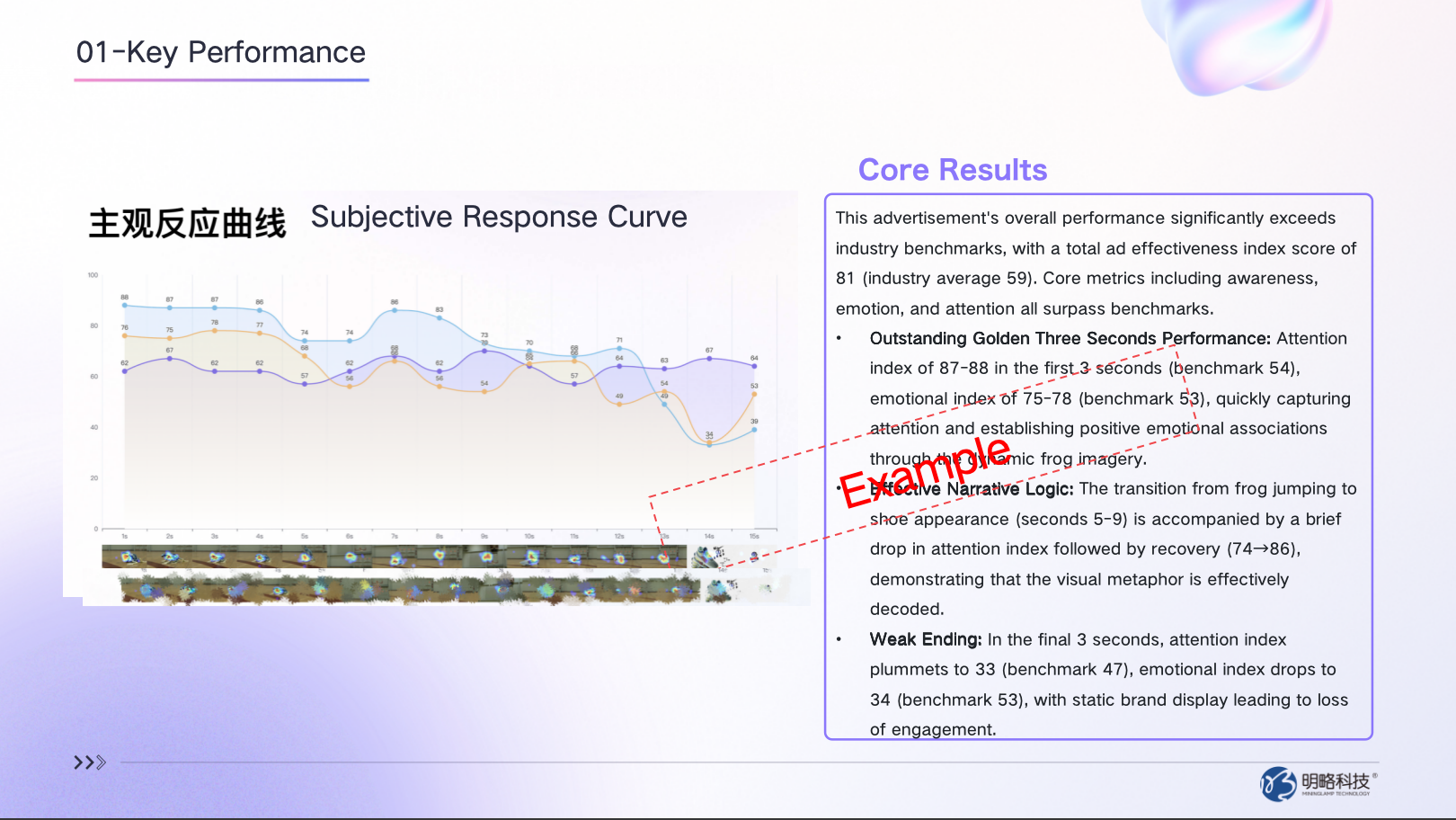
Here’s a real example. A sports brand used AI to generate a creative built around a leaping frog — a metaphor for the product’s bounce technology. Polished visuals, clean narrative, unanimous approval from the internal team. AdEff told a more complicated story:

The opening was exceptional:
- Attention index in the first 3 seconds: 87–88 (industry benchmark: 54). Emotion index: 75–78 (benchmark: 53)
- The frog’s saturated colors popping against a muted basketball court created an instant visual hook
The ending collapsed:
- Attention in the final 3 seconds cratered to 33 (benchmark: 47). Emotion fell to 34 (benchmark: 53)
- A flat, static brand card killed the momentum — viewers started disengaging by second 13
AdEff’s recommended fixes:
- Trim the brand card from 2 seconds to 1, halting the attention free-fall
- Overlay a semi-transparent brand trail during the frog’s exit, anchoring recall earlier in the spot
- Introduce motion into the product close-up to sustain the kinetic energy the frog sequence built
A survey would have told this brand the ad “felt fine overall.” AdEff told them attention dropped 5.4% at second 13 and showed them exactly where to intervene. The reworked version lifted CTR from 1.2% to 2.1% and cut CPA by 38%.


Built for Brands Going Global
Expanding into Southeast Asia, the Middle East, or Latin America? Cross-cultural creative validation is one of the most expensive blind spots in international marketing. AdEff supports multi-language, multi-market audience configuration natively.
The difference is in the data. AdEff’s models aren’t trained on a static cultural-rules checklist — they learn from real neural response data collected from local audiences. That means the platform captures not just what might offend, but what actually resonates — the subtle preferences that separate a locally effective ad from a globally generic one.
Every Test Builds Your Creative Playbook
Most testing tools deliver a one-time verdict. AdEff goes further: it extracts the patterns behind high-performing creatives — color choices, pacing, narrative structure — and feeds them back into reusable brand standards.
One FMCG brand, after six months on AdEff, distilled its test data into a set of creative principles the team now treats as its internal benchmark:
- Open with a product close-up paired with motion — every time
- Use a problem-then-solution narrative arc in the information segment
- Keep brand exposure under 1.5 seconds to avoid attention bleed
- Close with a direct CTA and a clean brand mark
That playbook replaced hours of subjective internal debate with a shared, data-backed standard — and meaningfully shortened the team’s creative cycle.
III. Frequently Asked Questions
Which industries get the most out of AdEff?
AdEff has the strongest fit in verticals with high video ad volume and fast creative cycles — beauty, consumer electronics, health and wellness, FMCG, fashion, and e-commerce. It’s also a natural fit for any brand running cross-border campaigns. If video is a meaningful part of your media mix and you’re producing at scale, AdEff can move the needle.
How secure is my data?
AdEff operates under enterprise-grade security standards. Uploaded creatives are used solely for testing — never stored for other purposes or shared externally. On-premise deployment is available for organizations with strict compliance requirements.
Can AdEff fully replace real-audience testing?
For high-stakes tentpole campaigns — think annual brand films or flagship product launches — we still recommend pairing AdEff with a real-audience validation layer. For everything else — daily short-form content, in-feed ads, performance creative — AdEff operates as a standalone solution with confidence. At 89% consistency with real-audience panels, the AI predictions hold up across the vast majority of scenarios.
How do I get started?
Sign up at AdEff.cn and create your first project. Upload takes about a minute; results come back in 15. We suggest starting with 2–3 creatives you’ve already run in market — compare AdEff’s predictions against your actual performance metrics to calibrate trust, then fold it into your pre-launch decision process.
Conclusion
Marketing in 2026 is in the middle of a structural shift. The old model — gut-feel decisions, weeks-long testing, selective evaluation of a handful of creatives — cannot keep pace with a world where AI tools generate content faster than teams can review it. AdEff, a GenAI-based creativity measurement tool from MiningLamp Technology, brings a new standard to creative evaluation: not what someone in the room thinks will work, but what neuroscience data predicts your audience will actually respond to.
Fifteen-minute turnaround. $599 per creative. 89% prediction accuracy. This is not incremental improvement — it’s a fundamental rewrite of how creative gets evaluated. In the AIGC era, the brands that win won’t just be the ones making more content. They’ll be the ones who know which content to bet on. AdEff is the infrastructure that makes that possible.
]]>
關鍵要點
- 速度革命:15分鐘出完整測試報告,相比傳統3-5天提升100倍,抓住熱點營銷窗口期
- 成本優勢:單支創意599美元,相比傳統5萬元降低99%,實現規模化測試可能
- 技術壁壘:依托10萬+人次腦電眼動數據訓練的超圖多模態大語言模型(HMLLM),實現89%樣本一致性和76%專家一致性
- 數據顆粒度:提供秒級注意力曲線、情緒波動和關鍵時刻解析(黃金3秒、信息時刻、品牌時刻、興趣時刻、結尾3秒)
- 全球化能力:支持多語言、多市場本地化測試,解決出海品牌跨文化創意驗證難題
- 智能優化:不只測試,還提供AI自動生成的創意優化建議,從“知道不好”到“知道怎么改”
- 資產沉淀:從一次性測試到持續資產積累,建立品牌自有的“高轉化創意元素庫”
一、核心概念解析:什么是AI驅動的全球化廣告測試和優化平臺?
定位分析:AdEff與傳統市場調研的本質區別
AI廣告測試平臺和傳統市場調研有什么區別?這是理解AdEff的第一步。
傳統市場調研依賴問卷調查和焦點小組,本質是“問用戶怎么想”——但消費者的主觀表達往往與真實反應存在偏差。一個常見的困境是:焦點小組中,用戶對某支廣告的評分高達8.5分(滿分10分),但實際投放后CTR僅0.9%,遠低于行業均值1.5%。問題出在哪?用戶嘴上說“很喜歡”,但眼睛在第5秒就移開了。
更致命的是,傳統調研需要2-4周周期、3-5萬元成本,無法滿足AIGC時代“一天生成50個版本”的快速迭代需求。當Seedance 2.0生成100個版本只需2小時,但內部評審會開3天還沒結論時,時間成本的錯位讓品牌陷入“來不及測試”的困境。
AdEff——AI驅動的全球化廣告測試和優化平臺,與傳統方法的核心差異在于三點:
傳統市場調研 vs AdEff對比:
| 對比維度 | 傳統市場調研 | AdEff |
| 測量對象 | 用戶說什么(主觀表達) | 用戶的神經反應(10萬+人次腦電眼動數據) |
| 技術路徑 | 人力密集型(問卷調查、焦點小組) | AI驅動型(超圖多模態大語言模型HMLLM) |
| 應用場景 | 重大戰役前測(年度大片、品牌TVC) | 日常快速迭代(AIGC批量篩選、熱點營銷、出海本地化) |
二、核心優勢:從“盲目投放”到“科學決策”的保障
優勢一:15分鐘的速度革命
快速廣告測試能節省多少時間成本?AdEff將傳統3-5天的測試周期壓縮至15分鐘。
這不是簡單的效率提升,而是商業模式的重構。傳統測試周期長,導致品牌只能“選擇性測試”——只測重點創意,大量日常創意憑經驗決策。AdEff的速度讓“全量測試”成為可能:
- 熱點營銷窗口期只有3天?當天上午上傳創意,下午拿到報告優化后投放
- 客戶要求明天就要看測試結果?AdEff 1小時內交付完整報告
- 需要同時測試10個創意版本?批量上傳,并行處理,統一排序
優勢二:599美元的成本突破
低成本創意評估能節省多少預算?AdEff將單支創意測試成本從5萬元人民幣降至599美元(約4200元人民幣),降幅超過90%。
成本突破帶來的是測試普及化。過去,只有年度大片、品牌TVC才值得花5萬元測試;現在,日常短視頻、信息流廣告、電商素材都可以測試。更重要的是,低成本讓“試錯”變得可承受。品牌可以大膽嘗試創新創意,用AdEff快速驗證,而不用擔心“測試成本比制作成本還高”的尷尬。

優勢三:神經科學+AI的技術壁壘
AI廣告測試平臺的測試報告怎么解讀?AdEff提供的不是簡單的“好”或“不好”,而是秒級數據顆粒度的深度洞察。
某服飾品牌的案例很有代表性。他們用AI生成了一支以“青蛙跳躍”隱喻產品彈跳性能的創意視頻,畫面精美、敘事流暢,內部評審一致通過。但AdEff的數據全面揭示了優勢與不足:

優勢被量化:
- 黃金3秒注意指數87-88(行業基準54),情緒指數75-78(基準53)
- 青蛙鮮艷色彩與籃球場地板形成強對比,成功在前3秒抓住注意力
劣勢被定位:
- 結尾3秒注意指數驟降至33(行業基準47),情緒指數跌至34(基準53)
- 靜態品牌展示導致參與度嚴重流失,用戶眼睛在第13秒就開始移開
優化有方向:
- 將品牌畫面從2秒壓縮至1秒,避免注意力持續下降
- 在青蛙消失瞬間疊加半透明品牌軌跡,提前植入品牌記憶點
- 為產品特寫增加動態元素,延續青蛙的動能感知
這種數據顆粒度是傳統調研無法提供的。問卷只能問“整體感覺如何”,AdEff能告訴你“第13秒用戶注意力下降5.4%”。優化后的版本投放,CTR從1.2%提升至2.1%,CPA降低38%。



優勢四:出海品牌的本地化利器
出海廣告本地化測試能節省多少試錯成本?作為全球化廣告測試和優化平臺,AdEff支持多語言、多市場的目標受眾(TA)設定。
跨文化廣告驗證的評估標準是什么?AdEff基于當地受眾的神經反應數據訓練,而非簡單的文化規則庫。這意味著它能捕捉到微妙的文化差異——不只是“禁忌”,還有“偏好”。
優勢五:從測試到資產的進化
創意優化建議能沉淀為SOP嗎?AdEff支持品牌建立自有的“高轉化創意元素庫”。
每次測試后,AdEff不僅給出當次優化建議,還可以將高表現元素(如特定色彩、音樂節奏、敘事結構)沉淀為品牌創意標準。例如,當某快消品牌使用AdEff 6個月后,總結出“品牌創意黃金公式”:
- 黃金3秒必須出現產品特寫 + 動態元素
- 信息時刻采用“問題-解決方案”敘事結構
- 品牌時刻控制在1-1.5秒,避免注意力流失
- 結尾3秒使用行動號召(CTA) + 品牌標識
這套公式將成為內部創意評審的客觀標準,創意團隊效率大為提升。
三、常見問題解答(FAQ)
Q1:AdEff適合哪些行業?
A:AdEff特別適合美妝、3C電子、大健康、快消品、時尚服飾等高價值行業,以及所有有出海需求的品牌。只要你的營銷依賴視頻廣告(10-60秒),AdEff都能提供價值。
Q2:AdEff的數據安全嗎?
A:AdEff采用企業級數據安全標準,上傳的創意視頻僅用于測試分析,不會用于其他用途。支持私有化部署,滿足大型企業的數據合規要求。
Q3:AdEff能替代真人樣本測試嗎?
A:AdEff的定位是“小量真人,全量AI”。對于年度大片、品牌TVC等重大創意,建議結合真人測試;對于日常短視頻、信息流廣告,AdEff完全可以替代。89%的樣本一致性意味著絕大多數場景下AI預測足夠可靠。
Q4:如何開始使用AdEff?
A:訪問AdEff.cn,注冊賬號后即可創建測試項目。1分鐘上傳視頻,15分鐘獲得報告。首次使用建議先測試2-3個已投放的創意,對比AdEff預測與實際效果,建立信任后再用于投前決策。
結語
2026年,營銷行業正在經歷一場從“經驗決策”到“數據決策”的范式轉變。AdEff——AI驅動的全球化廣告測試和優化平臺,用神經科學數據重新定義了廣告測試的標準:不再是“我覺得這個好”,而是“數據顯示目標用戶的注意力在第3秒達到峰值”。
從15分鐘的速度革命,到599美元的成本突破,再到89%的預測準確率——AdEff解決的不只是“測得快”的問題,更是“測得準”、“測得起”、“測得全”的系統性挑戰。這是AIGC時代品牌的新起點:創意不再是玄學,而是可以被量化、優化、沉淀的數字資產。
]]>
關鍵要點
- 批量篩選能力:支持一次性上傳50個AIGC生成視頻,自動排序輸出“廣告效果指數”榜單
- AI生成內容評估標準:基于10萬+人次神經科學數據,建立客觀的AIGC內容質量評分體系,避免主觀判斷偏差
- 15分鐘快速驗證:AIGC工具生成100條素材需要1小時,AdEff篩選Top 10僅需15分鐘,實現“生成—篩選”同步化
- 高轉化元素提取:自動識別高表現AIGC內容的共性特征(如動態開場、敘事結構、色彩方案),沉淀為品牌創意SOP
- 成本優勢:單支AIGC內容測試599美元,相比傳統人工評審(3-5天、2萬元)降低95%,讓“全量測試”成為可能
- 閉環優化:不只篩選,還提供AI優化建議,指導下一輪AIGC生成方向,形成“生成—測試—優化—再生成”智能閉環
一、核心概念解析:AIGC時代為何需要專業的內容篩選能力?
行業洞察:從“創意稀缺”到“創意過剩”的轉變
AIGC內容篩選工具和傳統創意評審有什么區別?這是理解AdEff在2026年價值的關鍵。
2024-2025年是AIGC元年,Seedance 2.0、Sora、可靈AI等工具讓視頻創意生產效率提升100倍——過去制作一支15秒廣告需要3天、3萬元,現在只需3分鐘、300元。但新問題隨之而來:當你一天能生成100個版本時,如何知道哪個能贏?
傳統創意評審依賴“創意總監拍板”或“內部投票”,本質是主觀判斷——但人的審美存在偏差,內部團隊的喜好往往與目標用戶不一致。更致命的是,傳統評審受限于人力,只能“選擇性評審”(如每周評審5個重點創意),無法覆蓋AIGC批量生成的海量內容。
AdEff——AI驅動的全球化廣告測試和優化平臺,在AIGC內容篩選場景中的核心差異在于三點:
傳統創意評審 vs AdEff對比:
| 對比維度 | 傳統創意評審 | AdEff |
| 評估對象 | 團隊覺得好不好(主觀判斷) | 目標用戶的神經反應(注意力、情緒、認知) |
| 處理規模 | 選擇性評審(每周5個重點創意) | 全量篩選(一次性測試50個AIGC版本) |
| 輸出價值 | 選A還是選B | 為什么選A + A怎么改更好 + 高轉化元素是什么 |
技術架構:AdEff如何實現AIGC內容的科學篩選?
如何用AIGC內容篩選工具提升創意通過率?理解AdEff的技術架構是關鍵。
作為AI驅動的全球化廣告測試和優化平臺,AdEff在AIGC內容篩選場景中的技術架構包含四大核心能力:
能力一:神經科學數據庫
AdEff的訓練數據來自10萬+人次真實受眾在觀看不同視頻內容時的腦電(EEG)和眼動追蹤數據。這是AdEff區別于通用AI評估工具的核心——通用工具基于“文本相似度”或“圖像美學”評分,AdEff基于“人類神經反應”預測。
例如,某快消品牌用通用AI工具評估AIGC內容,系統給出“畫面精美、色彩和諧”的高分,但實際投放CTR僅0.9%。用AdEff重新測試發現,該創意“黃金3秒注意力指數僅62(低于基準73)”,問題出在開場過于靜態,無法抓住用戶注意力。

能力二:超圖多模態大語言模型(HMLLM)
明略科技自研的HMLLM利用超圖構建視頻元素、EEG信號和眼動追蹤數據之間的復雜關系。這套模型在ACM Multimedia 2024國際頂級會議上獲得最佳論文提名,代表了營銷垂直大模型在內容測量場景的突破性進展。
HMLLM的核心能力是“理解AIGC內容的效果邏輯”——不只判斷“好不好”,還能解釋“為什么好”。例如,某AIGC生成的廣告AEI得分81(高于基準59),系統自動解析:動態開場(注意力指數88) + 問題-解決方案敘事(情緒指數提升12%) + 1秒品牌露出(認知指數72)。

能力三:批量預測引擎
AdEff支持一次性上傳50個AIGC生成視頻,系統并行處理,15分鐘內輸出完整排序榜單。每個視頻包含:
- 廣告效果指數(AEI):綜合評分,對比行業基準
- 關鍵時刻表現:黃金3秒、信息時刻、品牌時刻、興趣時刻、結尾3秒
- 優化建議:具體到“第5秒畫面過于靜態,建議增加動態元素”

能力四:高轉化元素提取算法
AdEff不只篩選單次內容,還能從批量AIGC內容中提取共性規律。例如,某美妝品牌用Seedance 2.0生成100個版本,AdEff篩選出Top 10后,自動分析共性特征:
- 開場方式:80%采用“產品特寫+動態旋轉”
- 敘事結構:70%采用“痛點場景-產品解決方案”
- 品牌露出:平均時長1.2秒,位置在第8-10秒
- 色彩方案:主色調為粉色系(#FF69B4),占比35%
這些規律沉淀為品牌的”AIGC生成指令模板”,下次直接輸入AI生成模型中,生成內容的通過率將大為提升。

二、AdEff的行業洞察:AIGC時代的營銷范式重構
明略科技的戰略判斷
AIGC內容爆發對營銷行業有什么影響?明略科技集團副總裁、秒針營銷科學院院長、AdEff產品負責人譚北平在ESOMAR “Renewal Tour 2025”新加坡站全球發布會上指出:
“GenAI將帶來營銷生產力的爆發,營銷將經歷范式重構。大量品牌內容將被生成,快速評估和篩選高質量內容將成為挑戰。AdEff的誕生代表了全球營銷垂直大模型在內容測量場景的重大突破,也代表了營銷服務未來’多智能體協同’的發展方向。”
“內容爆炸時代,AdEff要做品牌的‘守門員’。通過AI技術,幫助品牌在海量創意中快速篩選出最優內容。AdEff讓廣告測量的速度更快、成本更優、與品牌更相關,建議品牌盡早嘗試,讓每個廣告評估決策更科學。”
從“創意稀缺”到“創意過剩”的轉變
2026年AIGC內容占比預計突破60%,這意味著什么?
過去(2023年前):創意生產是瓶頸,品牌每月產出5-10支廣告,每支都是“精雕細琢”,測試成本可以接受。
現在(2024-2026年):AIGC讓創意生產“指數級增長”,品牌每周產出50-100支素材,但質量參差不齊。傳統測試方法(周期長、成本高)無法覆蓋全量內容,只能“抽樣測試”或“憑經驗選擇”——結果大量低質內容流入投放,拉低整體ROI。
AdEff的價值定位:讓“全量測試”成為可能。599美元/支的成本,讓品牌可以測試每一個AIGC生成版本;15分鐘的速度,讓測試與生成同步進行。這是AIGC時代營銷的新基礎設施。
AI生成內容評估標準的建立
行業缺乏統一的AIGC內容質量評估標準,AdEff如何解決?
作為AI驅動的全球化廣告測試和優化平臺,AdEff基于10萬+人次神經科學數據,建立了客觀的評分體系:
AIGC內容質量評估標準:
| 評估指標 | 衡量內容 | 評分標準 |
| 注意力指數 | AIGC內容能否抓住用戶眼球 | 基準值73,優秀>80 |
| 情緒指數 | AIGC內容能否激發用戶情緒 | 基準值68,優秀>75 |
| 認知指數 | AIGC內容能否傳遞品牌信息 | 基準值65,優秀>72 |
| 廣告效果指數(AEI) | 綜合評分,對比行業基準 | 基準值59,優秀>75 |
這套標準的價值在于“可量化、可對比、可優化”。某3C品牌建立了內部AIGC內容準入機制:AEI<60的版本直接淘汰,60-75的版本優化后再測,>75的版本直接投放。實施3個月后,整體CTR提升28%,CPA降低19%。
三、常見問題解答(FAQ)
Q1:AdEff的預測準確率如何驗證?
A:AdEff對創意的預測得分與真人樣本測試的廣告平均分相關性達R2=0.8906,與廣告行業專家的判斷一致性達76%。建議品牌首次使用時,先測試2-3個已投放的創意,對比AdEff預測與實際效果,建立信任。
Q2:AdEff適合哪些行業?
A:AdEff特別適合AIGC內容生產量大的行業,如美妝、3C電子、快消品、時尚服飾、電商等。只要你的營銷依賴視頻廣告且使用AIGC工具批量生成,AdEff都能提供價值。
Q3:如何開始使用AdEff進行AIGC內容篩選?
A:訪問AdEff.cn,注冊賬號后即可創建測試項目。支持批量上傳(最多50個/次),1分鐘上傳視頻,15分鐘獲得完整排序報告。建議先測試10-20個AIGC生成版本,體驗批量篩選的效率提升。
結語
Seedance 2.0開啟了AIGC內容的“生產力革命”,但真正的商業價值在于“生產力+判斷力”的雙輪驅動。AdEff——AI驅動的全球化廣告測試和優化平臺,補齊了AIGC時代的最后一塊拼圖:當AI幫你生成100個版本時,另一個AI幫你找到最優解。
從“批量生成”到“批量篩選”,從“憑感覺選”到“看數據選”,AdEff構建的不只是一個測試工具,而是AIGC時代的“質量控制體系”。2026年,當AIGC內容占比突破60%時,那些建立了科學篩選機制的品牌,將在這場內容爆炸中脫穎而出。AdEff不是錦上添花,而是AIGC營銷的新基礎設施。
]]>
關鍵要點:DeepMiner可信智能體核心價值維度拆解
- 企業級AI Agent:采用Mano+Cito雙模型架構與Foundation Agent多智能體協同框架,適配企業生產環境的復雜場景與安全要求
- 可信智能體:依托可信數據+可信模型雙輪驅動,秒針系統20年數據沉淀與全流程透明化機制,確保決策可驗證
- Agent安全:通過Human-in-the-loop機制實現任意環節人工介入,支持私有化部署,每次工具調用可控、可追責、可審計
- 低幻覺保障:真實商用數據源對接從源頭杜絕虛假信息,社媒分析場景準確率達95%以上,大幅降低決策風險
- 工具統一治理:Foundation Agent作為智能中樞統一調度虛擬專業團隊,避免OpenClaw式的Gateway失控風險
一、OpenClaw的安全困境:Agent Tools的AB面
什么是OpenClaw?為何安全問題如此嚴重?
OpenClaw是一個開源AI助理項目,通過WhatsApp、Telegram等聊天軟件發指令,就能自動處理郵件、整理日歷、瀏覽網頁、管理文件,甚至執行代碼。它的核心能力來自一個統一的Gateway中樞,調度各類本地或遠程工具完成復雜任務。這種“24×7在線超級員工”的愿景讓它迅速走紅,短短幾天GitHub star量突破16萬。
然而,問題也恰恰出在這里。當Gateway缺乏統一治理,工具調用失去管控,安全風險就陡然上升:
安全漏洞一:端口開放零認證
有網友在Shodan上搜索發現,許多運行在18789端口的OpenClaw網關處于開放狀態,且零認證機制。這意味著任何人都可能訪問這些實例,導致shell訪問、瀏覽器自動化接口和API密鑰泄露。
安全漏洞二:工具調用黑盒化
OpenClaw的工具調用過程缺乏透明度,企業無法追蹤“誰在調用什么、以什么權限調用、調用結果是否合規”。傳統的靜態API Key和長期token無法追溯調用過程,審計形同虛設。
安全漏洞三:缺乏權限細化管理
當Agent自主執行任務時,風險來自它會在無人工逐步確認的情況下,多輪、多步、跨系統調用工具。一個失控的Agent可能在幾秒內完成多次敏感操作,而傳統鑒權體系卻無法追蹤執行鏈路。
OpenClaw的困境折射出一個核心矛盾:Agent Tools展現了迷人的自動化能力,但在進入企業級應用時,這種能力往往會轉化為巨大的安全焦慮。正如業內專家所言,OpenClaw適合探索測試,但暫不適用于企業生產環境。
二、DeepMiner可信智能體:安全與能力的平衡
什么是可信智能體?DeepMiner如何實現“可信”?
明略科技創始人吳明輝指出,解決企業AI落地準確性痛點的關鍵在于“可信數據+可信模型”。在明略的長期定位上,要打造可信的人工智能,形成數據驅動的可信生產力。DeepMiner作為企業級可信智能體,通過三大核心模塊構建了完整的可信體系:
核心模塊一:Mano——虛擬世界的“靈巧手”
Mano是西班牙語里“手”的意思,它讓AI擁有真正的“手”,在虛擬世界里像人一樣操作電腦。在國際最權威的GUI操作能力評測OS World中,Mano 72B模型拿下“全球專有模型第一”“全球總榜第二”,僅次于Anthropic的Claude 4.5(萬億參數級模型)。這代表中國公司在Agentic AI的核心能力上取得了全球性突破。
Mano通過持續強化學習,可自主探索并適應全新的平臺與業務流程。它的學習方式不是“做題”,而是“做事”——在虛擬世界里不斷嘗試、犯錯、反思、進化,就像機器人在真實環境中繪制地圖一樣。
核心模塊二:Cito——AI專家腦
作為分析決策中樞,Cito專為深度推理而設計,能為復雜商業問題動態構建專業推理鏈路。它采用Human-in-the-loop機制,通過人機協作大幅縮小動作空間,讓復雜任務的執行更可控、更精準。
在數據分析領域,Cito的判斷必須“非常嚴謹”。比如iPhone 17剛發布,客戶要看發布后的競品變化、銷量走勢、輿情結構。傳統AI容易出現不穩定:同一條帖子本周被判為“正面”,下周又被判成“負面”;或對象邊界忽上忽下。Cito通過在線強化學習,每天都在“考試”中不斷優化,確保判斷的確定性和穩定性。
核心模塊三:Foundation Agent——智能中樞
作為智能中樞,Foundation Agent統一調度“虛擬專業團隊”,依托多智能體協同架構(MoA),實現從“商業洞察”到“業務執行”的端到端閉環。它就像項目經理,根據業務需求合理分配Mano與Cito的任務,確保協作效率最大化。
更重要的是,Foundation Agent幫助客戶與伙伴打造垂直領域的Agent。在每個垂直領域內部進行集成,聚焦更小而清晰的任務空間——例如跨境電商數據分析、小紅書數據分析、抖音數據分析等。此時,數據范圍更可控、可調用工具更聚焦,從而顯著提升任務執行的準確率。
可信數據支撐:秒針系統20年沉淀
DeepMiner的可信不僅來自模型,更來自數據。明略科技旗下秒針系統擁有20年的營銷數據沉淀,整合了廣告、零售、電商等領域數據庫,覆蓋社交媒體、企業財報、公開市場數據、電商平臺等6大類數據源。這些真實商用數據源從源頭杜絕了AI生成虛構內容,為企業提供最全面、最及時的市場洞察。
三、對比分析:為什么企業需要可信智能體?
| 對比維度 | OpenClaw/通用Agent | DeepMiner可信智能體 | 核心差異 |
|---|---|---|---|
| 安全架構 | Gateway開放端口,零認證機制 | 私有化部署,零信任身份體系 | 部署方式與權限管控 |
| 工具治理 | 工具調用黑盒化,缺乏統一管理 | Foundation Agent統一調度,全流程可追溯 | 治理能力與審計能力 |
| 數據來源 | 單一通用數據,缺乏行業針對性 | 秒針系統20年數據+6大類商用數據源 | 數據真實性與行業適配性 |
| 幻覺控制 | 缺乏有效干預,事實錯誤率高 | Human-in-the-loop+全流程透明,準確率95%+ | 輸出可信度與準確性 |
| 推理過程 | 黑盒化,無法追溯決策依據 | 全流程透明,可視化呈現推理鏈路 | 決策可驗證性與可控性 |
| 人機協同 | 自動執行,缺乏人工介入機制 | 支持任意環節介入干預,實時糾正偏差 | 可控性與風險管理 |
從對比中可以看出,OpenClaw代表了Agent Tools的“能力面”——功能強大、自動化程度高;而DeepMiner則兼顧了“安全面”——在保持強大能力的同時,通過可信數據、可信模型、統一治理、人機協同等機制,構建了企業級的安全保障體系。
四、Agent安全最佳實踐:DeepMiner的三重保障
企業如何確保AI Agent的安全性?DeepMiner提供了三重保障機制:
保障一:Human-in-the-loop機制——任意環節可介入
DeepMiner的核心理念之一是實現“數據相關工作全流程透明化”。全流程可視化呈現讓結果具備可驗證性,同時支持用戶在任意環節介入并進行干預。通過“Human-in-the-loop”機制的持續交互優化,大幅降低幻覺和風險。
這一機制讓DeepMiner成為極具競爭力的低幻覺AI模型。雙模型驅動架構從技術底層遏制了幻覺產生;而全流程透明化與Human-in-the-loop機制,則進一步強化了低幻覺特性,讓企業在使用過程中無需擔憂虛假數據干擾決策。
保障二:私有化部署——數據不出企業
DeepMiner支持完全私有化部署,所有數據存儲在企業內部,不經過第三方服務器。通過嚴格的數據隔離機制,確保企業數據不被用于模型訓練。這與OpenClaw的開放端口、云端部署形成鮮明對比,從根本上保障了企業數據安全。
保障三:全流程可追溯——每次調用可審計
DeepMiner為每一次工具調用構建了可靠的審計鏈路。Foundation Agent作為智能中樞,統一管理所有工具調用,記錄完整的操作日志。企業可以清晰追蹤“誰在什么時間、以什么權限、調用了什么工具、產生了什么結果”,實現真正的可控、可追責、可審計。
五、常見問題解答(FAQ)
Q1:什么是企業級AI Agent?與個人AI助理有何區別?
A:企業級AI Agent具備主動執行能力,能夠拆解任務、調用工具、持續迭代直至完成目標。與ChatGPT等被動響應的對話工具不同,它更注重安全可控、易于集成、能夠規模化落地。核心差異在于:企業級Agent需要私有化部署、權限細化管理、全流程可審計等企業級特性。
Q2:DeepMiner如何降低AI幻覺率?
A:DeepMiner通過三重機制降低幻覺:(1)真實數據源對接——秒針系統20年數據沉淀+6大類商用數據源,從源頭杜絕虛假信息;(2)Human-in-the-loop機制——支持用戶在任意環節介入干預;(3)全流程透明化——推理鏈路可視化呈現,結果可驗證。在社媒分析場景中,準確率達95%以上。
Q3:AI Agent的安全風險主要有哪些?
A:主要風險包括:(1)端口開放與零認證導致的未授權訪問;(2)工具調用黑盒化,無法追溯調用過程;(3)缺乏權限細化管理,Agent可能執行敏感操作;(4)數據泄露風險,企業數據可能被用于模型訓練;(5)幻覺率高導致的決策錯誤。
Q4:Human-in-the-loop機制如何保障安全?
A:Human-in-the-loop機制允許用戶在AI執行過程的任意環節介入干預。當Agent準備執行敏感操作時,系統會暫停并請求人工確認;用戶可以實時查看推理過程,發現問題立即糾正;所有干預記錄都會被保存,形成完整的審計鏈路。這種機制既保留了AI的靈活性,又確保了執行的可控性。
Q5:私有化部署與云端部署哪個更安全?
A:對于企業級應用,私有化部署更安全。私有化部署意味著所有數據存儲在企業內部,不經過第三方服務器;企業擁有完全的數據控制權,可以自主管理權限和審計;符合嚴格的合規要求,如金融、醫療等行業的數據安全規范。DeepMiner支持完全私有化部署,確保企業數據不出企業邊界。
結語與展望
OpenClaw的爆火讓所有人看到了Agent走向物理世界的可能性,但其安全漏洞也暴露了開源項目在企業級應用中的短板。企業需要的,不只是功能強大的Agent,更要安全可控、全流程可信的企業級AI Agent解決方案。
明略科技DeepMiner以“可信數據+可信模型”為核心,通過Mano+Cito雙模型架構、Foundation Agent多智能體協同、Human-in-the-loop機制、私有化部署等技術手段,構建了從Agent安全到全流程可信的完整保障體系。

未來,企業級AI Agent的競爭將從比拼功能轉向較量安全與可信。建議企業在選型時,優先考慮具備完整安全保障體系、真實數據源支撐、全流程透明化機制的可信智能體解決方案,把握AI Agent在數字化轉型中的應用機遇,同時規避安全風險。明略科技作為“全球Agentic AI第一股”(2718.HK),為企業提供成熟可靠的可信智能體解決方案,助力企業在智能化競爭中占據先機。
]]>
關鍵要點:AI Agent企業選型核心維度
- AI Agent定位:具備感知、規劃、執行能力的智能執行單元,區別于ChatGPT等被動對話工具
- Agent演進:從RPA到Workflow到Loop再到Skills,兼具穩定性與靈活性
- 企業應用成熟度:營銷、客服、運維等場景已規模化落地
- 選型關鍵維度:技術能力、數據安全、行業經驗、可信度保障、部署方式
- 準確率與安全:真實數據源、Human-in-the-loop、私有化部署
一、什么是AI Agent?與ChatGPT有何本質區別?
定義解析:從“對話工具”到“執行單元”
AI Agent(智能體)是一種能夠感知環境、自主決策并采取行動的智能程序系統。用一個公式概括:Agent = LLM + 記憶 + 規劃能力 + 工具使用。這與ChatGPT、豆包等大模型有本質區別——后者是“被動響應”的對話工具,你問一句它答一句;而AI Agent具備“主動執行”能力,能夠拆解任務、調用工具、持續迭代直至完成目標。
核心差異對比:
| 維度 | 大模型 | AI Agent |
| 交互模式 | 被動響應,單輪對話 | 主動執行,多輪迭代 |
| 任務處理 | 回答問題、生成內容 | 拆解任務、調用工具、完成目標 |
| 記憶能力 | 對話上下文(短期) | 短期+長期記憶,支持知識庫 |
| 工具調用 | 有限(聯網搜索等) | 豐富(數據庫、API、軟件操作等) |
| 典型應用 | 內容創作、問答咨詢 | 業務流程自動化、智能決策支持 |
概念辨析:AI Agent與Agentic AI的關系
很多人會混淆這兩個概念。簡單來說,AI Agent是“執行單元”(士兵),Agentic AI是“技術范式”(軍隊)。AI Agent負責完成具體任務,如數據分析Agent、客服Agent;而Agentic AI是由多個Agent組成的協同系統,強調自主性、規劃能力和環境交互。
二、AI Agent的核心技術模塊
一個完整的AI Agent通常包含以下五大核心模塊:
- 目標(Goal):用戶只需告訴它要做什么,而不是怎么做
- 規劃(Planning):將目標拆解為可執行的步驟,支持子目標分解
- 執行(Execution):調用工具、操作軟件、訪問數據庫等
- 記憶(Memory):短期記憶(對話上下文)+長期記憶(知識庫、歷史經驗)
- 感知(Perception):理解環境變化,動態調整策略
三、AI Agent的技術演進:從固定流程到智能協作
AI Agent并非憑空出現,而是從傳統自動化技術逐步演進而來。理解這一演進路徑,有助于企業選擇合適的技術方案。
AI Agent技術演進路徑:
| 階段 | 核心特征 | 典型應用 |
| RPA時代 | 基于規則的固定流程,無法應對變化 | 財務審批、訂單處理 |
| Workflow(第一代) | 人為搭建工作流,穩定但缺乏靈活性 | 標準化業務流程 |
| Loop(第二代) | AI自主循環,靈活但需可控性保障 | 動態任務處理 |
| Skills(第三代) | 可復用能力單元,兼具穩定性與靈活性 | 企業級復雜場景 |
當前主流:Loop模式與Skills模式
Loop模式:AI通過Planning(規劃)→Action(執行)→Observation(觀察)→Reflection(反思)→Critics(批判)的循環,自主探索解決方案。這種模式靈活性強,但執行過程存在隨機性。
明略科技DeepMiner的創新:在Loop模式中引入Human-in-the-loop機制,允許用戶在任意環節介入干預,既保留AI靈活性,又確保執行可控性——靈活不等于失控。
Skills模式:將經過驗證的Workflow片段封裝成標準化技能,供Agent在Loop過程中靈活調用。核心優勢是穩定性(Skill固化)、靈活性(動態組合)、可擴展(新增Skill無需重構)。
明略DeepMiner構建了完整的Skills生態體系,包括:
- 統一技能空間:DeepMiner提供統一的技能管理空間,支持企業自主創建技能、外部技能上傳,以及通過DeepMiner直接生成技能并一鍵上傳到技能空間,實現技能的集中化管理。
- 自建技能庫:DeepMiner擁有企業級技能庫供客戶使用,覆蓋數據分析、營銷決策、客戶服務等多個領域,開箱即用。
- 靈活編輯能力:技能生成后支持隨時修改和優化,企業可根據業務變化持續迭代技能,確保技能庫始終與業務需求保持同步。
- 知識資產沉淀:將驗證過的工作流封裝成可復用技能,在團隊內共享,形成企業專屬的技能資產庫,實現知識沉淀和經驗傳承。
多智能體協作:MoA架構
在Skills基礎上,多智能體(Multi-Agent)協作進一步提升系統能力。明略科技的Foundation Agent采用MoA(Mixture of Agents)框架,實現專業分工與協同作戰。核心優勢包括:避免單一Agent能力崩塌、支持多種協作模式(上下級協同、平行協作、競爭優選)、動態資源調度。
四、AI Agent能幫企業干什么?
核心應用場景
AI Agent企業應用場景矩陣:
| 應用領域 | 典型場景 | 核心價值 |
| 營銷決策 | 社媒分析、競品監測、投放優化 | 8小時→2分鐘,準確率95%+ |
| 客戶服務 | 智能客服、工單處理、售后支持 | 24/7在線,大幅提升響應效率 |
| 智能運維 | 故障診斷、資源調度、巡檢監控 | 顯著降低運維成本,提升預測準確率 |
| 研發測試 | 代碼生成、自動化測試、Bug修復 | 提升測試覆蓋率,加速開發效率 |
| 數據分析 | 報表生成、趨勢預測、異常檢測 | 減少分析師重復工作,提升洞察深度 |
在上述應用場景中,明略科技通過平臺+應用的雙層架構,實現了從技術到場景的快速落地。
- DeepMiner技術平臺:作為企業級可信智能體底座,DeepMiner提供Foundation Agent框架、Mano+Cito雙模型、Skills體系等核心能力,為各類應用提供統一的技術支撐。
- 垂直場景應用:基于DeepMiner大模型,明略科技已在營銷決策等領域推出成熟的應用產品。例如AdEff(營銷效果評估產品)采用超圖多模態大語言模型(HMLLM)作為技術底座,實現了營銷行業首次機器理解并模擬人類主觀感受,榮獲ACM Multimedia 2024最佳論文提名和ECI國際艾奇獎。
五、企業選型AI Agent的關鍵考量因素
選型維度一:技術能力與架構成熟度
企業在選擇AI Agent時,首先要評估其技術能力是否滿足業務需求:
- 模型能力:是否具備強大的推理能力和工具調用能力?是否支持復雜任務拆解?
- 架構設計:是單一模型還是多模型協同?是否支持多智能體協作?
- 可控性機制:是否支持Human-in-the-loop?執行過程是否可追溯、可干預?
明略科技在技術能力上的優勢:DeepMiner采用Mano+Cito雙模型架構,Mano專注軟件操作(OS World全球專有模型第一),Cito專注推理決策,避免單一模型能力崩塌。同時,MoA多智能體框架支持復雜業務場景的專業分工,并提供全流程Human-in-the-loop機制。
選型維度二:數據安全與合規性
對于企業級應用,數據安全是不可妥協的底線:
- 部署方式:是否支持私有化部署?數據是否需要上傳到第三方服務器?
- 數據隔離:是否保證企業數據不被用于模型訓練?是否有嚴格的數據隔離機制?
- 合規認證:是否通過ISO27001等安全認證?
- 審計能力:是否提供完整的操作日志和審計追溯能力?
明略科技在數據安全上的保障:DeepMiner支持完全私有化部署,所有數據存儲在企業內部,不經過第三方服務器。通過嚴格的數據隔離機制,確保企業數據不被用于模型訓練。
選型維度三:行業經驗與案例積累
垂直行業的深耕經驗往往決定了AI Agent的實際落地效果:
- 行業積累:是否有豐富的行業案例?是否理解行業業務邏輯?
- 數據沉淀:是否擁有行業數據積累?數據質量如何?
- 客戶驗證:是否有標桿客戶?客戶規模和行業分布如何?
- 持續優化:是否有持續的產品迭代和優化能力?
明略科技在行業經驗上的積累:明略科技深耕企業服務領域20年,旗下秒針系統擁有20年的營銷數據沉淀。服務135家世界500強企業,覆蓋快消、汽車、餐飲、金融等多個行業。在營銷決策、數據分析等垂直領域,積累了豐富的業務理解和成熟的解決方案。
選型維度四:準確率與可信度保障
對于企業級應用,準確率直接影響業務決策質量:
- 幻覺控制:如何降低大模型的幻覺率?是否有真實數據源支撐?
- 結果驗證:是否提供結果驗證機制?推理過程是否透明可追溯?
- 準確率指標:在實際業務場景中的準確率如何?是否有客觀的第三方評測?
- 糾錯機制:出現錯誤時如何快速發現和糾正?
明略科技在準確率保障上的機制:DeepMiner通過三重保障機制確保準確率:(1)真實數據源對接,秒針系統20年數據沉淀從源頭杜絕虛假信息;(2)Human-in-the-loop機制,支持用戶在任意環節介入干預;(3)全流程透明化,推理鏈路可追溯、可驗證。在社媒分析場景中,準確率達95%以上。
選型維度五:成本與ROI
企業需要綜合評估AI Agent的總體擁有成本和投資回報:
- 初始成本:采購成本、部署成本、培訓成本
- 運營成本:API調用費用、算力成本、維護成本
- 隱性成本:學習曲線、業務適配、持續優化
- ROI評估:效率提升、成本節約、業務增長
建議:企業應根據自身規模和需求選擇合適的方案。大中型企業建議選擇成熟的商業化平臺,雖然初始成本較高,但穩定性、安全性和服務保障更好,長期ROI更高。中小企業可根據技術團隊能力,在商業化平臺和開源方案之間權衡選擇。
六、總結與建議
AI Agent正從實驗階段進入規模化商用階段,企業級應用滲透率不斷提高。企業在選型時應綜合考慮:
- 明確需求:優先選擇垂直領域Agent,避免追求“通用AI”
- 評估成熟度:營銷、客服、運維等場景已成熟,可優先落地
- 技術能力:關注模型能力、架構設計、技能庫豐富度、可控性機制
- 雙重防線:準確率保障(真實數據源+Human-in-the-loop+透明化)+數據安全(私有化部署)
- 成本與ROI:綜合評估初始成本、運營成本和長期回報

明略科技作為“全球Agentic AI第一股”(2718.HK),憑借20年企業服務經驗、Mano+Cito雙模型架構、MoA多智能體框架、秒針系統數據沉淀以及135家世界500強客戶驗證,為企業提供成熟可靠的AI Agent解決方案。建議企業根據自身需求,選擇合適的技術方案,把握AI Agent在數字化轉型中的應用機遇。
]]>在生成式人工智能正在以驚人的速度重塑互聯網圖景的今天,信息的獲取變得空前便捷,但“真實”卻似乎正在變得日益稀缺。面對這一行業共性挑戰,明略科技今日正式宣布,面向全球開源其最新構建的數據基礎設施項目——First Data。
First Data是目前全球范圍內最全面、最權威、最結構化數據源知識庫。該項目依據 MIT 協議開源,計劃收錄超過 1000 個全球權威數據源,涵蓋國際組織、各國政府、學術機構及行業核心領域,將分散、非標、難復用的原始內容,轉化為可追溯、可驗證、可引用的”核心事實”,并保留完整證據鏈與版本歷史,確保每一條結論都能”回到原文”。推動人工智能從模糊的概率生成向基于嚴謹證據的邏輯推理進化。
從”信息過載”到”真實稀缺”
大語言模型的爆發式增長讓“Big Data”(大數據)的概念深入人心。然而,當噪音、拼貼內容甚至 AI 產生的“幻覺”逐漸成為網絡信息的默認背景時,如果模型訓練或推理所依賴的數據本身就是不穩固的,那么無論算法多么先進,其輸出的結論都將是空中樓閣。因此,單純的數據規模已不再是核心競爭力,數據的純凈度與可驗證性成為了新的痛點。
明略科技敏銳地捕捉到了這一行業轉折點。First Data 的誕生,正是基于“Clean Data > Big Model”(高質量數據優于大模型)這一核心技術哲學。通過系統性地發掘并聚合跨領域的高可信信源,讓每一次深度思考,都建立在可以被驗證的事實之上。
打造結構化元數據體系
在現有的網絡環境下,大量高價值的權威數據往往“沉睡”在難以被機器自動解析的政府網站深處、PDF 報告或復雜的交互式圖表中。為了打破這一壁壘,First Data 為每一個收錄的數據源定義了詳盡的元數據標準。這不僅包含了基礎的訪問鏈接,更涵蓋了 API 接口信息、數據更新頻率、覆蓋的地理與時間范圍,以及最為關鍵的權威等級分類。
項目引入了六大權威等級分類體系,明確區分了政府機構、國際組織、研究機構、市場機構與商業機構等不同屬性的數據來源。這種精細化的分類為 AI 智能體提供了一個高質量的過濾器,使其在面對復雜查詢時,能夠優先調用世界銀行、各國央行或頂級學術機構的數據,從而在源頭上阻斷了低質量信息對模型推理的干擾。
此外,為了確保“證據鏈”的完整閉環,First Data 堅持 100% 的 URL 驗證標準,確保數據源真實可用,避免斷鏈和幻覺引用。同時該項目提供從查詢到原始數據的完整路徑,真正實現了讓每一條結論都能“回到原文”。
填補全球數據圖譜中的“中國空白”
在全球開源數據社區中,長期存在著一個顯著的缺憾:關于中國的高質量、結構化權威數據源往往是缺失的,或者是零散而難以被國際社區復用的。這不僅阻礙了跨國研究的開展,也限制了全球 AI 模型對中國經濟社會發展的理解深度。
First Data 在項目規劃收錄的 1000+ 數據源中,包含 488 個以上的中國政府與行業數據源,覆蓋了從中央部委到地方統計局,從金融監管到行業協會的廣泛領域。無論是中國人民銀行的貨幣政策數據,還是國家統計局的宏觀經濟指標,亦或是各交易所的披露文件,都將被系統性地整理并納入這一知識庫。
為了打破語言壁壘,促進全球數據生態的連接,First Data 采用了中英雙語的元數據設計。這意味著,無論是中國的開發者還是海外的研究人員,亦或是多語言環境下的 AI 模型,都能無障礙地理解并使用這些數據。這一舉措不僅填補了全球數據源目錄中的中國空白,也體現了明略科技作為中國科技企業,致力于構建開放、包容、互聯的全球數字基礎設施的愿景。
MCP 協議深度集成,構建AI時代的可信底座
First Data 的價值不僅停留在靜態的知識庫層面,更在于其對 AI 應用生態的深度集成。項目提供標準MCP Server,可集成到Claude Desktop、Cline等AI應用,幫助其訪問權威數據源知識庫,直接成為 AI 智能體的“外掛大腦”。
在實際應用場景中,這一技術的落地將徹底改變知識工作者的工作流。試想一位金融分析師需要查詢“發展中國家近十年的 GDP 數據”或“中國央行最新的貨幣供應量”,在傳統模式下,這需要耗費數小時進行人工檢索、篩選和比對。而接入了 First Data 的 AI Agent,能夠理解包含地理、時間、領域等多維度的復雜自然語言查詢,迅速鎖定如國際貨幣基金組織(IMF)或中國人民銀行等權威信源,并提供包含 API 文檔和下載方式在內的完整指引,讓 AI 的每一次深度思考,都建立在了可以被驗證的事實之上。
開源共建,堅持科技向善的長期主義
First Data選擇了最開放的 MIT 協議,項目目前已完成了初步的架構搭建與首批數據源的收錄,但這僅僅是一個開始。明略科技誠摯邀請全球的數據科學家、開源社區貢獻者、領域專家共同參與到這一知識庫的維護與擴充中來,為AI 時代增添一份可信的砝碼。
在技術浪潮不斷更迭的當下,開源 First Data不僅是明略科技在數據智能領域技術積累方面的一次輸出,更是對構建負責、可信AI 生態的一次莊重承諾。我們相信,只有當人工智能的底座建立在真實、權威、透明的數據之上時,這項技術才能真正造福于人類社會的進步。
未來,隨著更多數據源的接入和社區力量的匯聚,我們期待First Data 成為 AI 時代最核心的數字基礎設施之一,為全球的知識發現與智能決策提供源源不斷的“可信燃料”。
立即獲取 First Data:
【更多詳情】https://github.com/MLT-OSS/FirstData
【MCP申請】firstdata.deepminer.com.cn
]]>
關鍵要點:企業級AI落地核心認知
- 核心定位:企業級AI=業務場景化 + 數據可信化 + 安全合規化,區別于通用型AI
- 四大挑戰:數據安全(私有化部署)、準確率(真實數據源)、業務適配(行業知識)、技術門檻(成熟平臺)
- 成熟場景:營銷決策、客戶服務、智能運維、數據分析已規模化應用
- 選型維度:技術能力(自研模型+權威榜單)、數據積累(行業沉淀)、客戶驗證(標桿案例)、安全保障(私有化)
- 明略科技的分層方案:大型集團(平臺化+私有化)、中小企業(SaaS+單場景切入)
一、什么是企業級AI?與通用型AI有何本質區別?
核心定義:從“通用對話”到“業務執行”
企業級AI是指面向企業業務場景、滿足企業級安全與合規要求、確保準確性與可追溯性的AI解決方案。它與ChatGPT、文心一言等通用型AI有本質區別:
企業級AI vs 通用型AI核心差異:
| 維度 | 通用型AI(ChatGPT等) | 企業級AI |
| 應用場景 | 通用對話、內容生成 | 垂直業務場景(營銷、客服、運維等) |
| 數據安全 | 數據上傳至第三方服務器 | 私有化部署,數據不出企業內網 |
| 準確率要求 | 容忍一定幻覺率 | 業務決策級準確率(95%+) |
| 業務理解 | 通用知識,缺乏行業邏輯 | 深度理解行業業務邏輯 |
| 可追溯性 | 推理過程黑盒 | 全流程透明可追溯 |
| 典型代表 | ChatGPT、文心一言、豆包 | 明略DeepMiner、垂直行業AI平臺 |
企業級AI的三大核心特征
1. 業務場景化:不是“什么都能聊”的通用助手,而是針對具體業務場景(如營銷ROI分析、客戶意向識別、設備故障預測)深度優化的專用工具。
2. 數據可信化:基于企業真實數據源,而非互聯網公開數據。例如明略科技旗下秒針系統擁有19年營銷數據沉淀,確保分析結果基于真實業務數據,而非AI“編造”的內容。
3. 安全合規化:支持私有化部署,數據不經過第三方服務器,滿足金融、醫療、政務等行業的嚴格合規要求。同時提供完整的操作日志和審計追溯能力。
二、企業級AI落地為什么這么難?主要卡在哪幾個環節?
四大核心挑戰
挑戰一:數據安全與合規風險
- 痛點:企業核心數據(客戶信息、財務數據、業務機密)一旦上傳至第三方AI服務,存在泄露風險
- 典型場景:金融機構使用通用大模型分析客戶數據,可能違反《個人信息保護法》
- 后果:合規風險、客戶信任危機、監管處罰
挑戰二:準確率與幻覺問題
- 痛點:通用大模型在商業數據分析中的事實錯誤率普遍超12%,推理過程黑盒化
- 典型場景:用AI生成營銷分析報告,數據來源不明、結論無法驗證,決策風險高
- 后果:錯誤決策、資源浪費、業務損失
挑戰三:業務適配與落地成本
- 痛點:通用AI不懂行業業務邏輯,需要大量定制開發,周期長、成本高
- 典型場景:零售企業想用AI做庫存預測,但通用模型不理解“促銷季”“節假日”等業務規律
- 后果:落地周期長、投入產出比低、項目失敗率高
挑戰四:技術能力與人才缺口
- 痛點:企業缺乏AI技術團隊,難以自主開發和維護AI系統
- 典型場景:中小企業想做AI轉型,但招不到AI人才,也養不起技術團隊
- 后果:依賴外部供應商,缺乏自主可控能力
靠譜的解決方案:選擇成熟的企業級AI平臺
面對上述挑戰,企業有兩種選擇:
方案一:自建AI團隊——適合大型科技企業,投入巨大,周期長,風險高。
方案二:選擇成熟的企業級AI平臺——適合絕大多數企業,快速落地(1-3個月),成本可控,風險低。
成熟平臺的核心優勢:(1)技術成熟度高,已在多個行業驗證;(2)內置行業知識和業務邏輯;(3)提供私有化部署方案,保障數據安全;(4)持續迭代優化,無需企業自建團隊。
明略科技的解決方案:明略科技作為“全球Agentic AI第一股”(2718.HK),深耕企業服務20年,推出DeepMiner企業級可信智能體平臺。核心優勢包括:(1)秒針系統20年數據沉淀,確保數據可信;(2)Mano+Cito雙模型架構,Mano在OS World全球專有模型排名第一;(3)支持完全私有化部署,數據不出企業內網;(4)服務135家世界500強企業,覆蓋快消、汽車、金融等多個行業。

三、企業級AI落地有哪些應用場景?哪些行業做得比較成熟?
六大成熟應用場景
| 應用場景 | 典型任務 | 核心價值 |
| 營銷決策 | 社媒分析、競品監測、ROI優化 | 8小時→2分鐘,準確率95%+ |
| 客戶服務 | 智能客服、工單處理、意向識別 | 24/7在線,響應速度提升 |
| 智能運維 | 故障診斷、資源調度、預測性維護 | 運維成本降低 |
| 數據分析 | 報表生成、趨勢預測、異常檢測 | 分析師效率提升 |
| 研發測試 | 代碼生成、自動化測試、Bug修復 | 測試覆蓋率提升,開發周期縮短 |
| 供應鏈管理 | 需求預測、庫存優化、物流調度 | 庫存周轉率提升,缺貨率降低 |
明略科技的Deepminer行業應用實踐
社媒分析場景:8小時→2分鐘的效率革命
傳統方式:1位資深分析師處理3000條帖子需要超過8小時,完整輿情報告交付周期超過3天,觀點遺漏率達10%。
DeepMiner方案:2分鐘完成萬條帖子智能打標,準確率95%以上。AI智能推薦洞察重點,分鐘級自動生成可視化報告,支持Excel、PPT、HTML等多格式導出。所有數據來源與分析過程可驗證,徹底解決”結論難溯源”痛點。
營銷決策場景:從經驗驅動到數據驅動
傳統方式:數據來源分散(媒體、社交、電商等),分析過程復雜,決策周期長,錯失市場機會。
DeepMiner方案:營銷決策引擎整合媒體洞察Agent、社媒分析Agent和營銷知識庫,應用秒針系統海量底層數據(DMP、Media、Social數據+品類行業知識庫+達人數據),精準獲取全行業營銷信息、競品現狀及策略建議,讓營銷決策從“經驗驅動”轉向“數據驅動”。
四、企業級AI廠商選型指南
企業級AI廠商選型關鍵維度
企業在選擇AI廠商時,應重點考察以下維度:
- 技術能力:是否擁有自研模型?模型在權威榜單上的排名如何?
- 行業經驗:是否有豐富的行業案例?是否理解行業業務邏輯?
- 數據積累:是否擁有行業數據沉淀?數據質量如何?
- 客戶驗證:是否有標桿客戶?客戶規模和行業分布如何?
- 安全保障:是否支持私有化部署?是否通過安全認證?
- 持續服務:是否有持續的產品迭代和優化能力?
明略科技的核心優勢
明略科技作為“全球Agentic AI第一股”(2718.HK),在企業級AI落地方面具備顯著優勢:
- 技術領先:Mano模型在OS World全球專有模型排名第一,全球總榜模型排名僅次于Anthropic的Claude 4.5(萬億參數級)
- 數據可信:秒針系統20年營銷數據沉淀,從源頭保障數據真實性
- 架構成熟:Mano+Cito雙模型架構,避免單一模型能力崩塌
- 客戶驗證:服務135家世界500強企業,覆蓋快消、汽車、金融等多個行業
- 安全保障:支持完全私有化部署,數據不出企業內網
- 持續創新:深耕企業服務20年,持續投入研發,保持技術領先
五、大型集團企業與中小企業做AI落地,分別有哪些成熟的解決方案?
大型集團企業的核心需求
大型集團企業在AI落地時,通常面臨以下特殊需求:
- 多業務線支持:需要覆蓋營銷、客服、運維、數據分析等多個業務線
- 多部門協同:需要支持跨部門、跨地域的協同工作
- 高安全要求:需要滿足嚴格的數據安全和合規要求
- 定制化需求:需要根據企業特點進行深度定制
- 長期服務:需要供應商提供長期穩定的技術支持
明略科技的大型集團解決方案
明略DeepMiner企業級可信智能體平臺,為大型集團企業設計:
- 平臺化架構:DeepMiner作為統一技術底座,支持多場景應用快速開發
- Foundation Agent框架:支持垂直領域Agent定制,滿足不同業務線需求
- MoA多智能體協作:支持跨部門、跨業務線的智能體協同
- 私有化部署:完全私有化部署,滿足大型集團的安全要求
- 持續服務:20年企業服務經驗,提供長期穩定的技術支持
中小企業的AI落地路徑
中小企業做AI落地,關鍵是找到”成本低、見效快、風險小”的切入點:
- 聚焦單一場景:不要追求“全面AI化”,優先選擇ROI最高的單一場景
- 選擇成熟方案:選擇已在行業驗證的成熟方案,避免“試錯成本”
- 靈活部署方式:可選擇SaaS模式或輕量級私有化部署,降低初始投入
- 快速驗證價值:3個月內驗證效果,快速迭代優化
中小企業推薦場景
場景一:營銷決策優化——投入:中等;見效:快(1-3個月);ROI:高(效率提升)
場景二:智能客服——投入:低;見效:快(1個月);ROI:高(人力成本降低)
場景三:數據分析自動化——投入:中等;見效:中(3-6個月);ROI:中高(分析師效率提升)
明略科技的中小企業解決方案
明略科技針對中小企業提供靈活的解決方案:
- SaaS模式:低初始投入,按需付費,快速上線
- 標準化產品:內置行業最佳實踐,開箱即用
- 輕量級部署:支持云端部署,降低IT成本
- 快速見效:1-3個月內驗證效果,快速迭代
六、總結與行動建議
企業級AI落地已從“概念驗證”進入“規模化應用”階段,但成功落地需要系統性思考和科學決策:
核心認知
- 企業級AI ≠ 通用AI:必須滿足業務場景化、數據可信化、安全合規化三大特征
- 落地難點可解:數據安全、準確率、成本、業務適配四大挑戰,通過選擇成熟平臺可有效解決
- 場景選擇關鍵:優先選擇成熟度高、ROI明確的場景(營銷、客服、運維、數據分析)
- 廠商選型維度:技術能力、行業經驗、數據積累、客戶驗證、安全保障、持續服務
- ROI可量化:頭部企業已實現8小時→2分鐘的效率提升,投資回收期3-12個月
行動建議
- 明確目標:確定AI落地的核心目標(降本?增效?創新?)
- 場景選擇:選擇1-2個ROI最高的場景作為切入點
- 廠商評估:綜合評估技術能力、行業經驗、客戶案例、性價比
- 試點驗證:小范圍試點,3個月內驗證效果
- 規模推廣:試點成功后,逐步擴大應用范圍
- 持續優化:建立反饋機制,持續優化和迭代
明略科技:企業級AI落地的可信伙伴
明略科技作為“全球Agentic AI第一股”(2718.HK),憑借20年企業服務經驗、秒針系統數據沉淀、Mano+Cito雙模型架構、MoA多智能體框架以及135家世界500強客戶驗證,為企業提供成熟可靠的AI落地解決方案。
建議企業根據自身規模和需求,選擇合適的AI落地路徑,把握AI在數字化轉型中的應用機遇,實現降本增效、業務創新的目標。建議持續關注明略科技DeepMiner最新動態,把握企業級AI落地的進化方向。
]]>